

Editor’s Note: MapR products and solutions sold prior to the acquisition of such assets by Hewlett Packard Enterprise Company in 2019 may have older product names and model numbers that differ from current solutions. For information about current offerings, which are now part of HPE Ezmeral Data Fabric, please visit https://www.hpe.com/us/en/software/data-fabric.html
Original Post Information:
"authorDisplayName": ["Prasad Singathi","Maikel Pereira"], "publish": "2019-06-18T07:00:00.000Z", "category": ["machine-learning"],
Background
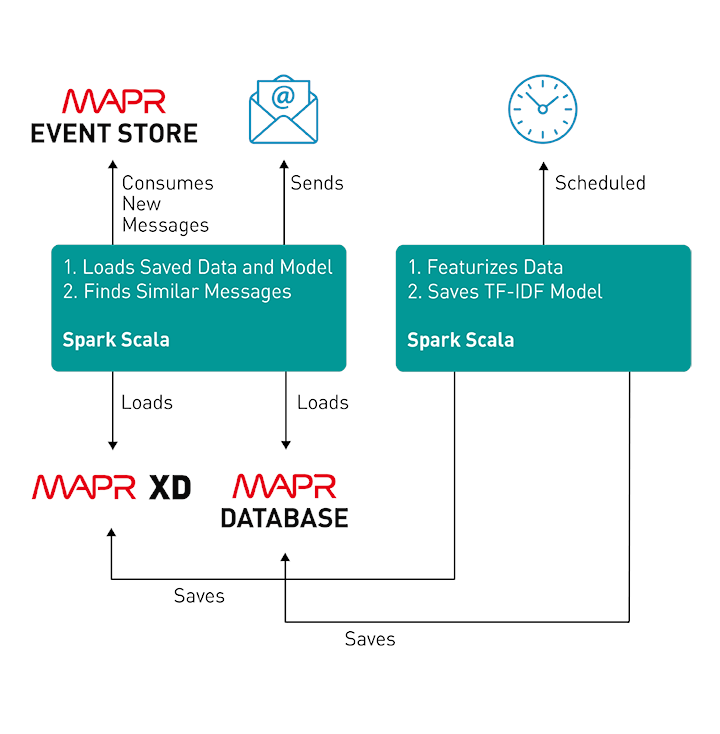
As a professional services group, we were tasked with providing a solution to automatically find messages in the archives that are similar to new messages and send them to the person asking the question.
To accomplish that goal, we decided to apply machine learning to the process, so that there is an automated program able to find similarities between the current message and the historical data. The algorithm used was term frequency—inverse document frequency (TF-IDF). TF-IDF is used in a variety of applications. Typical use cases include document search, document tagging, and finding similar documents.
Problem Description
The desired solution was built using two Apache Spark applications running in a MapR cluster: one of them uses the historical data to update data features and train the model on a regular basis, and the second one analyzes every new message and finds five similar ones.
Application 1 - Creates Features and Trains Model
This application was developed using Spark and Scala, and it can run on a schedule, depending on the needs. Here is what it does, step by step:
- Loads all messages from MapR Database. For the sake of brevity, we omit preprocessing steps like tokenization, stop words removal, punctuation removal, and other types of cleanup.
val rawEmaiData=spark.loadFromMapRDB("/googlegroups/messages") val rawEmaiDataDF=rawEmaiData.select("_id","bodyWithHistory","threadId","emailDate")
- Creates hashingTF, using HashingTF class available in Spark, and sets fixed-length feature vectors of 1000. It applies the hashing transformation to the document, resulting in the featurizedData.
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(1000) val featurizedData = hashingTF.transform(wordsData)
- Creates the IDF, and from the TF and the IDF, it creates the TF-IDF.
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features") val idfModel = idf.fit(featurizedData) val rescaledData = idfModel.transform(featurizedData)
- A UDF is necessary for pre-calculating sparse vector norm.
def calcNorm(vectorA: SparseVector): Double = { var norm = 0.0 for (i <- vectorA.indices){ norm += vectorA(i)*vectorA(i) } (math.sqrt(norm)) } val calcNormDF = udf[Double,SparseVector](calcNorm)
- Creates a TF-IDF corpus.
val normalized = rescaledData.withColumn("norm",calcNormDF(col("features")))
- Saves IDF model to MapR XD Distributed File and Object Store.
idfModel.write.overwrite().save("/googlegroups/save_model_idf")
- To save features vector to the MapR Database table, we have to convert the features vector to JSON format. For this, we create and register a UDF.
def toJson(v: Vector): String = { v match { case SparseVector(size, indices, values) => val jValue = ("type" -> 0) ~ ("size" -> size) ~ ("indices" -> indices.toSeq) ~ ("values" -> values.toSeq) compact(render(jValue)) case DenseVector(values) => val jValue = ("type" -> 1) ~ ("values" -> values.toSeq) compact(render(jValue)) } } } val asJsonUDF = udf[String,Vector](toJson)
- Finally, saves features vector to the MapR Database table.
val dfToSave = normalized.withColumn("rawFeaturesJson", asJsonUDF(col("rawFeatures"))).withColumn("featuresJson", asJsonUDF(col("features"))).drop("rawFeatures").drop("features") dfToSave.saveToMapRDB("/googlegroups/trained_model", createTable = false)
Application 2 - New Messages
The second application is a Spark Stream Consumer application that will execute the following steps:
- Loads the previously saved
idfModeland initializes a newHashingTFmodel.
val idfModel = IDFModel.load("path/to/serialized/model") val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(1000)
- Loads in memory and caches the data with the features saved previously.
val all = contextFuntions.loadFromMapRDB(argsConfiguration.trained).toDF all.cache()
- Creates a DataFrame with the current message.
val one = Seq((x._id,x.body)).toDF("_id", "contents") val newWords = prepareWords(one, "words") val newFeature = hashingTF.transform(newWords) val newRescale = idfModel.transform(newFeature) val normalized = newRescale.withColumn("norm2", UDF.calcNormUDF(col("features2")))
- Then, it finds the crossjoin DataFrame between the one element and all existing messages in the database and calculates the similarity.
val cross = normalized.crossJoin(all).drop(normalized.col("_id")) val cosine = cross.withColumn("similarity", UDF.calcCosineUDF(col("features"), col("features2"), col("norm"), col("norm2")))
- For this, it uses the cosine function implemented as follows and registered as a UDF.
def cosineSimilarity(vectorA: SparseVector, vectorB:SparseVector,normASqrt:Double,normBSqrt:Double) :(Double) = { var dotProduct = 0.0 for (i <- vectorA.indices){ dotProduct += vectorA(i) * vectorB(i) } val div = (normASqrt * normBSqrt) if( div == 0 ) (0) else (dotProduct / div) } udf[Double,SparseVector,SparseVector,Double,Double](cosineSimilarity)
- The result can then be ordered by similarity, in descending order, taking the top five elements.
val similarsDF = cosine.sort(desc("similarity")).select("similarity","_id").limit(5)
Conclusions
MapR provides the ecosystem needed for Apache Spark applications to run and scale as needed. It integrates all database and streaming platforms and enables the ability to do distributed processing. It efficiently integrates Spark with the database and the file system by extending it. Both capabilities, which are particularly useful for this solution, will be implemented in production as a feature of a bigger product in an effort to organize the Google Groups forum and with the intention of extending it to other data sources and realms. Since it is tested in a MapR cluster, all that would be needed is to install it and dedicate more resources when the moment comes.
Related
A Functional Approach to Logging in Apache Spark
Feb 5, 2021